在项目中做了很多失败的东东,这里展示其中一个,好水一篇文章。
算法的基本思路就是提取图像的SIFT特征,然后聚类生成多个视觉词汇作为图像的特征,构建图像特征数据库,搜索图像的时候,计算图像的视觉词汇,在数据库中查找具有相同视觉词汇的图像,然后进行一系列计算,筛选出他们中匹配的特征中的优质特征,统计数目,根据优质特征的数目进行排序,就得到了查询结果。会用到SIFT、Kmeans、BoW、grabCut、RANSAC和SVM等等算法,不过有的不会直接展示出来。
首先是获取图像的地址。每张图像的命名方式都一样,直接使用标签+空格+序号。
1 2 3 4 img_train = os.listdir('img/clothes/train' ) img_train = [os.path.join('img/clothes/train' , i) for i in img_train] img_val = os.listdir('img/clothes/val' ) img_val = [os.path.join('img/clothes/val' , i) for i in img_val]
利用grabCut进行前背景分割,计算出图像的掩膜。这个实际上后面部分展示的代码中好像没有用上,把Mask改为了None,要用的话,原本还配套了load_mask函数来加载保存了的mask,所以后面有的地方还是可能会出现load_mask这个函数。
1 2 3 4 5 6 7 8 9 def cul_mask (img ): mask = np.zeros(img.shape[:2 ], np.uint8) cv2.grabCut(img, mask, rect, bgdModle, fgdModle, 9 , cv2.GC_INIT_WITH_RECT) return mask2 for path in img_train+img_val: img = cv2.imread(path) mask = cul_mask(img) save(mask)
将图像的路径转为标签,方便后续操作。all_classes中保存了所有标签的名称。
1 2 3 4 5 all_classes = ['suit' , 'pants' , 'jeans' , 'coat' , 'hoodie' ] def path2class (path ): name = os.path.basename(path).split(' ' )[0 ] name = all_classes.index(name) return name
提取每个图像的SIFT特征。des_list中储存了所有的特征,des_list_per_img储存对应图像中的特征。进行聚类主要就是用des_list了。
1 2 3 4 5 6 7 8 9 10 sift = cv2.xfeatures2d.SIFT_create() des_list = np.zeros((1 , 128 )) des_list_per_img = [] for i, path in enumerate (img_train): print ('\r%.2f%%' %((i+1 ) / len (img_train) * 100 ), end='' ) img = cv2.imread(path, 0 ) kpts, des = sift.detectAndCompute(img, load_mask( path )) des_list = np.concatenate((des_list, des), axis=0 ) des_list_per_img.append(des) des_list = np.delete(des_list, [0 ], 0 )
搜索图像,返回图像id列表(这里的voc和word2img在函数外部)很快就会用上。这个函数的作用主要就是把有与检索图像具有相同words的所有图像返回,见if v > 1:,v就是单词的出现次数,只要出现了2次以上,就要返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 def search_k (img, key_words_num, mask=None ): sift = cv2.xfeatures2d.SIFT_create() kpts, des = sift.detectAndCompute(img, mask) test_features = np.zeros(key_words_num, "int" ) words, distance = vq(des, voc) for w in words: test_features[w] += 1 rlist = [] for i, v in enumerate (test_features): if v > 1 : rlist += word2img[i] rlist = np.unique(rlist) return rlist
通过修改key_words_num,多次运行,得出不同key_words_num时的效果。key_words_num表示kmean聚类中心的数目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 key_words_num_list = [50 , 300 , 600 , 1000 , 2500 , 5000 , 8000 ] mean_correct = [] mean_return = [] for key_words_num in key_words_num_list: print (key_words_num) voc, distance = kmeans(des_list, key_words_num, iter =1 ) im_features = np.zeros((len (img_train), key_words_num), "float32" ) for i in range (len (img_train)): words, distance = vq(des_list_per_img[i], voc) for w in words: im_features[i][w] += 1 word2img = [] for _ in range (key_words_num): word2img.append([]) for index, ft in enumerate (im_features): for i, v in enumerate (ft): if v > 0 : word2img[i].append(index) correct_num = [] all_num = [] for index, img_path in enumerate (img_val): img = cv2.imread(img_path) rlist = search_k(img, key_words_num) all_num.append(len (rlist)) count = 0 for r_id in rlist: r_path = img_train[r_id] if path2class(r_path) == path2class(img_path): count += 1 correct_num.append(count) mean_correct.append( np.average( correct_num ) ) mean_return.append( np.average( all_num ) )
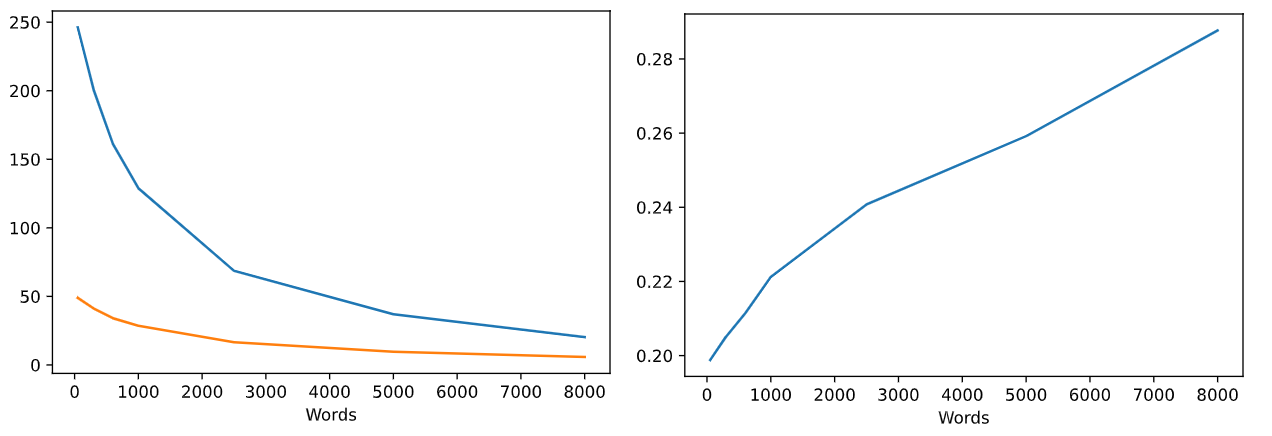
下面进行绘图操作。第一幅图展示返回图像张数和正确张数,第二张图展示的是召回率,非常low,因为这里返回图像的时候是按照有相同的words,并且次数大于2次,就返回,所以一开始words=50时,几乎就是把所有图像一股脑全部返回了,召回率就很低,最后words变多,图像之间能有相同的words的概率会下降,无关words减少的多,相关words减少的少,召回率就略微上去了。
1 2 3 4 5 6 7 8 9 plt.figure() plt.plot(key_words_num_list, mean_return, key_words_num_list, mean_correct) plt.xlabel('Words' ) plt.show() recall = np.array(mean_correct) / np.array(mean_return) plt.figure() plt.plot(key_words_num_list, recall) plt.xlabel('Words' ) plt.show()
看这个图也能看出来我的数据集是有多小,第一张图的黄色的线是正确返回数目,蓝色线是总共返回的数目,这两线越来越近,说明返回正确的比例越来越高,说明提高聚类中心的数目是有帮助的,不过黄色的线也越来越低,这个召回率最终会收敛到一定的值。当初我觉得我的数据集的图像相似度比较高,虽然数据集很小,但是召回率应该比现在高才对,实际上这张图对当初的我没有什么帮助,我当初认为召回率是先上升再下降,对应的最高点就是最佳的words数目了,但是这么多words,聚类太耗费时间,而且每次聚类都要先随机取点,略有影响,再加上数据集太小,可能提取不出那么多特征来聚类了。
下面是图像重排和搜索,重新排序能够让最相似的图像排在前面,对于mAP值而言有提高的帮助。rsort_1和rsort_2函数就对应了两种重排方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 def rsort_1 (rlist, des ): gm_score = [] gm_id = [] for test_id in rlist: bf = cv2.BFMatcher() matches = bf.knnMatch(des, des_list_per_img[test_id], k=2 ) good = [] for m, n in matches: if m.distance < 0.85 * n.distance: good.append(m) gm_id.append(test_id) gm_score.append( len (good) ) gm_score = -np.array(gm_score) gm_index = np.argsort(gm_score) real_id = [] for v in gm_index: real_id.append(gm_id[v]) return real_id def rsort_2 (rlist, img ): gm_score = [] gm_id = [] this_ft_proba = clf.predict_proba([ ext_ft(img) ]) for test_id in rlist: dist = np.linalg.norm(this_ft_proba - ext_ft_proba_per_img[test_id]) gm_score.append(dist) gm_id.append(test_id) gm_score = np.array(gm_score) gm_index = np.argsort(gm_score) real_id = [] for v in gm_index: real_id.append(gm_id[v]) return real_id def search (img, Topk, mask=None ): sift = cv2.xfeatures2d.SIFT_create() kpts, des = sift.detectAndCompute(img, mask) test_features = np.zeros(numWords, "int" ) words, distance = vq(des, voc) for w in words: test_features[w] += 1 rlist = [] for i, v in enumerate (test_features): if v > 1 : rlist += word2img[i] rlist = np.unique(rlist) real_id = rsort_2(rlist, img) return real_id[:Topk]
下面计算一下搜索5张图像的时候的mAP。这个好像看着还行,如果mAP=0.4的话,就是5张图像中对了两张,并且排序在前。不过这段代码有可能用错公式了,懒得再看了 ᖗ( ᐛ )ᖘ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 APs = {} for index, img_path in enumerate (img_val): img_q_cate = os.path.basename(img_path).split(' ' )[0 ] img = cv2.imread(img_path) rs = search(img, 5 , load_mask(img_path)) count_correct = 0 AP = 0 for i, rs_id in enumerate (rs): if img_q_cate == os.path.basename(img_train[rs_id]).split(' ' )[0 ]: count_correct += 1 AP += count_correct / (i+1 ) if count_correct == 0 : AP = 0 else : AP /= count_correct if img_q_cate not in APs: APs[img_q_cate] = [] APs[img_q_cate].append(AP) for a in APs: print (a+':' , np.average(APs[a]))
输出:
1 2 3 4 5 coat: 0.42055555555555557 hoodie: 0.6468055555555555 jeans: 0.45791666666666675 pants: 0.4727777777777778 suit: 0.5704166666666667
总的来说,非常失败,浪费了不少时间,我按照网上的算法直接进行TF-IDF、L2正则化,然后巴拉巴拉点乘排序,效果好像还好一些,就是数据和代码没有保存下来,但是数据集大的时候运行非常消耗内存,可见图像检索—-BOW(词袋)算法 ,网上很多都是这个算法,它这里面说当测试集为60张图片时,top5的正确率只有40%左右,这么一看,我测的是mAP,其值会小于等于正确率,似乎我的要好一些,不过我们相互用的数据集都不同,没有可比性,只能知道效果都不好。
其他参考:在OpenCV3中进行特征点筛选与优化 BOW 原理及代码解析 BoW(词袋)模型详细介绍